![]()
![]()
![]()
Any Web site that does more than just display pages will use Common Gateway Interface (CGI) programs. CGI programs provide support to many useful functions. Even basic things such as Hypertext Markup Language (HTML) forms require a CGI program to process the information and do something useful with it. Many people refer to CGI programs as scripts. For me, this term somehow diminishes the complexity that some CGI programs have. I prefer to call them CGI programs. CGI programs can exist as interpreted scripts or compiled binaries—in either form, they are programs.
The most popular languages used for developing CGI programs are sh (Bourne shell), Perl (Practical Extraction Report Language), and C. You can use any language from which you can access environment variables. Most, if not all, UNIX programming or scripting languages can do this because this support is really inherited from the shells. This means that, depending on the task at hand, you are free to choose a CGI development tool that matches your needs and program complexity—a good thing.
A CGI program is a program that conforms to certain conventions. Many people think that CGI is a protocol or a language or a specification. CGI is none of the above; it is a standard. In simplest terms, CGI is just a set of commonly used variables with the conventions used to access them. The variables provided by the CGI convention are used to exchange information between the HTTP server and a client program. In addition, CGI provides a means to return output to the browser. All output sent to stdout (the standard output stream) by a CGI program shows up on the Web browser, provided the right MIME-type header is sent by the CGI program.
If you want to execute a CGI program, you need to run a Web server like Apache because CGI transactions cannot be simulated by the browser. CGI calls happen only on the server side. On execution, most CGI programs will
At its most basic level, a CGI program will usually collect information from an HTML form, process data in the form, and then perform some action such as e-mailing data to a person. In its most complex form, there are virtually no limits to what can be done with a CGI program. CGI programs can interact with databases by fetching and storing various pieces of information to produce some sort of result.
Because of the stateless nature of the World Wide Web, there is no way to track a user from page to page using just conventional document-serving techniques. CGI allows communication, through a standard set of environment variables, between the HTTP server and a program running on the server computer—in this case, a CGI program. All sorts of things are possible with CGI that were not feasible with just HTML.
This basic capability of sending some data to a program via an HTTP server is responsible for a whole new way of creating client/server–type applications: the intranet. CGI programs permit the content of Web pages to be dynamic and relevant to what the user wants to see. I believe that in the future, many custom applications developed for private use by an organization (mission-critical applications) will be deployed as intranets—as Web-based applications. It makes sense. Instead of developing various versions of a program to match the mixed environment of today's office—PC, Macintosh, UNIX—you can develop a single version of your application that resides on a Web server. As long as there's a browser available for the machine you are using, you can access the application. Obviously, there are limitations, and some things are better done on the client side anyway. Java and other client-side programming tools will allow for more complex user-interface portions of the software to reside on the client, while the data persistence and other functionality happens on the server side.
Some environments, such as WebObjects from NeXT Software, Inc., provide many of the tools needed to create complex, real-world, Web-based applications today.
CGI programs can be written in any language that has access to environment variables. However, you will find that most CGI programs are written in Perl, C, sh, or Tcl. Perl is widely used because of its strengths in text processing; currently, most Web applications are heavily weighted toward searching for and retrieving textual data. However, the language you choose will depend on your programming abilities and the complexity of your CGI. This chapter is by no means intended to be a programming reference. If you don't know how to program, there are many books that will help you get started. This chapter, however, will cover the basics regarding what makes a CGI program different. I will discuss how to access data passed from a browser in languages such as Perl, C, and sh. Many of the examples will be in Perl because it offers many facilities that make some of the basic CGI development tasks easier.
Perl is an excellent choice for CGI programs. In its current version, 5.002 as of this writing, it provides object-oriented modular programming, an excellent regular expression engine, and the best free support of any language I've seen. Perl allows for very rapid development. It originally was developed as an improved sh-sed-awk hybrid, but it has evolved into a feature-rich, structured, object-oriented language suitable for many programming tasks. Perl is great for text processing, and it has the extremely useful associative array data type built right into the language—An associative array is basically a key/value pair relationship. Unlike a list array, the key or index portion of the array is a string—a feature that makes it quite easy to work with the CGI environment variables.
There aren't too many downsides to Perl. One, however, is that it generally runs slower than a compiled language such as C. Perl is an interpreted language rather than a compiled language. This means that the Perl interpreter must parse, assemble, and compile the code each time a Perl program is called. This adds overhead (albeit small) to running a Perl program. Another downside is that Perl can't (yet) generate a standalone executable file. There is an effort underway to create a Perl compiler, and an alpha version has actually been released, but it is not yet the "accepted" way to run Perl programs. Another downside of interpreted versus compiled programs is that anyone with enough cleverness can view your Perl source code within the Web tree.
Overall, though, Perl is an excellent language for CGI programming, and the one on which I will focus in this chapter.
C has long been the industry-standard workhorse language for both small and large projects. Development of CGI programs in C usually takes a little longer, due to compiling time and the nature of C itself, but the resulting program runs orders of magnitude faster than any interpreted code. There aren't as many shortcuts as there are in Perl, however. For example, memory for dynamic arrays isn't automatically allocated or deallocated; you need to do all your housekeeping yourself. In contrast, Perl will grow an array automatically, freeing your time to do other things. Overall, though, C is very robust and is well-suited to CGI programming; and if your CGI program needs critical performance, it is a good candidate for the task.
Some CGI programs are written as shell scripts. Although this may be quick and easy in some cases, sh is generally not suited for complicated programming. Use sh for the simplest of activities. Its advantages are that your system probably has a sh, or any of its variants, in it and, because sh is the environment, accessing environment variables is trivial.
The main problem with sh CGI programs is that it requires a bit of effort to decode encoded information sent to the CGI program via the QUERY_STRING environment variable or through the stdin or POST queries. There are a few tools on the Net that alleviate either of these problems quite a bit. I will cover these later.
You will find tons of useful information about programming for the Web on the Internet. The following are a few of my favorite sites and resources.
If you are interested in learning Perl , two great books written by the main developers of the language will provide about all the reference you will ever need:
On the Internet, Usenet carries many things. Some of the newsgroups to check are
news:comp.lang.perl.announce news:comp.lang.perl.misc news:comp.lang.perl.modules
A special note about the newsgroups for Perl: Do NOT post CGI-related issues to the comp.lang.perl.* hierarchy. Rather, divert any CGI-related questions to comp.infosystems.www.authoring.cgi. Only post to the Perl newsgroups as a last resort. There are many common questions already answered in this frequently asked questions (FAQ) document:
http://www.perl.com/perl/faq/perl-cgi-faq.html
In addition to answering many commonly asked questions about Perl, this FAQ contains pointers for everything else you could possibly imagine about Perl.
The latest version of the Perl software is available from any of the Comprehensive Perl Archive Network (CPAN) sites listed. Its aim is to be the only Perl archive you will ever need. The CPAN archive can be found at various locations. Table 5.1 gives a list of all known sites, at the time of this writing, grouped by continent.
For CGI topics, you may want to check out The CGI Book by William E. Weinman, published by New Riders, ISBN 1-56205-571-2. Another good book is CGI Programming Unleashed by Dan Berlin, published by Sams Publishing, ISBN 1-57521-151-3. HTML and CGI Unleashed by John December and Mark Ginsburg, published by Sams.net Publishing, ISBN 0-672-30745-6, is a complete guide for the development of your Web content. Another good book, although already showing some age, is Build a Web Site by Net.Genesis and Devra Hall, published by Prima Online Books, ISBN 0-7615-0064-2.
On the Internet , the following addresses are good resources to check:
http://www.boutell.com
Maintained by Thomas Boutell, this site has a lot of interesting Web information. It is also home to MapEdit, a PC and X Window map-creation tool; Wusage, a Web server statistics package; and cgic, a library of routines for programming CGI in C.
If you want to learn how to program in C, there are a few million books out there that will serve you equally well. The authoritative one, The C Programming Language by Brian W. Kernighan and Dennis M. Ritchie, published by Prentice-Hall, Inc., is a must.
Books are also available for sh programming; however, your system's online documentation may have enough to get you started. For those interested in using the csh as their command processor, check out The UNIX C Shell Field Guide by Gail and Paul Anderson, published by Prentice-Hall, ISBN 0-13-937468-X. This book is an excellent reference on csh and various UNIX commands that you can use to create powerful scripts that get real work done. Another helpful book is UNIX Unleashed, published by Sams Publishing, ISBN 0-672-30402-3. It covers UNIX commands, features, and utilities in depth .
The very first program most anyone writes in a new language is called Hello World!. The intention of Hello World! is to print the words Hello World, be it on the terminal or on a Web browser. I will provide you with three examples that say hello in Perl, C, and sh. Although I am not teaching you how to program, go get one of the books I've listed; These examples will show you what makes a CGI program different from other programs you may have developed.
The programs in Listings 5.1, 5.2, and 5.3 could have been written more compactly, but I have opted for multiple print calls and for placing of HTML tags one per line (unless the tag closes on the same line) for the sake of clarity. (If you are writing CGI, I assume that you are familiar with HTML tags; otherwise you may be well over your head, and you should perhaps take a look at Appendix D, "HTML Reference.")
Listing 5.1. Hello World! as a sh CGI .
#!/bin/sh # HelloInSh - A trivial example of a shell CGI # This program returns html content. The very first line of this # listing # Comments lines used for providing more information to the programmer # or documentation lines have the '#' character as the first character # in the line. The first # symbol is special, it's not a comment. # It informs the operating system to use the program /bin/sh # as the command interpreter for the script that follows. # The very first thing, we do on our CGI is tell the server # what type of data we are returning, in this case it is html: # echo Content-type: text/html # # then we need to add a single line blank line, that separates the # 'header' from the actual stuff in our output: # echo # # At this point we need to provide 'body' that includes all the usual # tags and structure required by html. # because some of the characters such as the angle brackets # are interpreted by the sh as a redirection, we need to enclose them # with a single quote: # echo '<HTML>' echo '<HEAD>' echo '<TITLE> Hello World!</TITLE>' echo '</HEAD>' echo '<BODY>' echo '<H1>Hello World!</H1>' echo '</BODY>' echo '</HTML>'
Listing 5.2. Hello World! as a Perl CGI program .
#!/usr/local/bin/perl # HelloInPerl, a trivial example of a CGI in Perl # # Output appropriate header for server, we included two newlines, the '\n'. # print "Content-type: text/html\n\n"; # # Use a 'here' document format for easy readability and avoid need for many # many printf() statements. All the lines following the print line are 'printed' # verbatim, until the 'STOP' tag is found. # print <<STOP; <HTML> <HEAD> <TITLE> Hello World!</TITLE> </HEAD> <BODY> <H1>Hello World!</H1> </BODY> </HTML> STOP # # Now we tell the operating system that this run of the program proceeded without # any errors by 'exiting' with a zero status. # exit(0);
Listing 5.3. Hello World! as a C CGI program .
/* HelloInC - A trivial example of a CGI in C. */
#include <stdio.h>
int main (void)
{
printf ("Content-type: text/html\n\n");
/* As our Perl or sh examples, the first thing to output is the Content-type */
printf("<HTML>");
printf("<HEAD>");
printf("<TITLE>Hello World!</TITLE>");
printf("</HEAD>");
printf("<BODY>");
printf("<H1>Hello World!</H1>");
printf("</BODY>");
printf("</HTML>");
return;
}
The C version of the program is the one that looks the oddest of the three examples. For one thing, C is more structured, and its syntax is more rigid. C is a compiled program, meaning that after you enter the code, you need to convert it into an executable program before you can run it. C offers low-level access to the OS, making it a very powerful programming language. Although CGIs in C are harder to implement that the equivalent Perl programs, C does have its own advantages. C programs run fast—very fast. If your CGI is one that does many things and your server is under a heavy load, you may have no choice but to create an efficient program that creates the least impact on your system. C is a great tool for this.
Perl and sh are interpreted languages. Interpreted programs are executed by an interpreter—such as the Perl, sh (Bourne shell), or another shell type program. Both languages allow you to do several things that would take many lines of code in C with very few commands. Both of these languages were designed with rapid development in mind.
In terms of debugging problems with your program, C may provide you with better tools that you can use to track problems in your code. Both Perl and sh provide you with ways to catch syntax errors, but certain types of errors may be a little harder to track.
I have talked about what a CGI is, and you have seen what a simple CGI looks like. At this point, you might be asking yourself how to run a CGI. If you have read this book in sequence, you will probably recall that execution of programs from the HTTP server can be a source of potential security problems, so CGI execution is usually restricted. By default, CGI programs exist in the /usr/local/etc/httpd/cgi-bin directory, or whatever other directory is defined by your ScriptAlias directive in your srm.conf file. The ScriptAlias directive is commented out from the default configuration. If you have not done so, you may want to remove the comment and restart the server. This will enable CGI execution for CGIs located in the cgi-bin directory.
Never, ever put a command interpreter such as Perl or any shell in your cgi-bin directory. Why? Think about it! That would make the executable available to anyone who wants to send it data. Even though the browser encodes data that is sent to the CGI, perverse minds will think of exploiting this security problem in their favor. In short, this is a huge security risk that is best avoided. Put your shells and command interpreters in a directory where the httpd daemon has no execution permission; /usr/local/bin is a very good place.
To test these CGI programs , just put them in your cgi-bin directory. Make sure your scripts are executable by setting the file mode to 755. You can do this easily from a command line by typing:
chmod 755 myscript
Replace myscript with the name of the file you want to make executable.
Also remember that the C version needs to be compiled before it is executed. Here's an easy way to compile it:
cc sourcefile.c -o binary
Replace sourcefile.c with the name of your C source file and binary with the name of the finished program. After a few seconds you should be left with an executable that you can run. If your system returns cc: command not found, you may want to try changing the command from cc to gcc.
If you named your CGIs as I suggested in the program comments in the listings, just move them to your cgi-bin directory and test the following URLs on your favorite browser:
http://localhost/cgi-bin/HelloInSh http://localhost/cgi-bin/HelloInPerl http://localhost/cgi-bin/HelloInC
You should get a result similar to the screen shown in Figure 5.1.
Figure 5.1. The output for the any of the Hello World! programs.
If you are having problems with the programs, see if you can get them to run on a terminal. If it will output the header and some HTML, and it doesn't give you an error, the problem may be with UNIX permissions. Recheck that your program is executable. If the problem is with a script, check that the location of the interpreter program is where I list it (the first line of the script). If it is not, change the first line to the absolute path of your command interpreter and try again (if the program is found anywhere in any of the directories specified by your path, it will be listed by using the whereis command. For more information on how to use the whereis program, please refer to your UNIX documentation). Note that the !# are required symbols that tell the shell that the script should be run by the specified command processor .
CGI programs run in an environment that is different from most programs. For one thing, most of the time they do not get input from stdin, the standard input stream. Because of this, input needs to be handled differently than in most programs. As I mentioned before, CGI passes values as environment variables . Environment variables are used extensively under UNIX as a way of communicating things like the location of your home directory and your mailbox, the capabilities of your terminal, and so on. When you execute a program, UNIX makes all of these settings available in case a program is interested in them.
In a similar manner to the UNIX shell, the HTTP server uses the environment mechanism to pass values to a CGI program. The HTTP server sets a number of environment variables prior to executing the CGI program. These variables provide information about the user, his software, and the server.
These environment variables can be accessed by name, and if your CGI calls other programs, these variables are inherited by the environment of the programs you call. The standard CGI 1.1 specification defines the variables discussed in the following sections.
The AUTH_TYPE variable is set to the type of authentication used to validate a request.
The CONTENT_LENGTH environment variable is set to the size of the data that was submitted with the request. The size of the data is specified in bytes. HTTP PUT and POST requests use this value to read that amount of bytes from stdin, the standard input stream. You shouldn't attempt to read any more data bytes than specified by this variable.
The CONTENT_TYPE variable is set to the Multipurpose Internet Mail Extensions (MIME) type or format submitted with the request. The format is expressed with a type/subtype syntax. If the data was submitted using the HTTP POST method, the value of this variable is set to application/x-www-form-urlencoded. The amount of data submitted is specified by the CONTENT_LENGTH variable.
The GATEWAY_INTERFACE variable is set to the version of CGI that the server implements. The syntax of the version follows a pattern CGI/version: CGI/1.1. As new variables are added to the CGI standard, the version number is increased. Your program should be aware of this version number to ensure that the variables you use are available in the environment setup by the server you are using. This variable is set for all requests.
The PATH_INFO variable is set to the Uniform Resource Identifier (URI). For practical purposes, a URI is just an URL that follows the string identifying the CGI script, like the following example:
http://www.company.com/cgi-bin/mycgi/a/b/c will be set to /a/b/c.
Your program can use this information to do whatever it wants, perhaps to pass extra settings (switches) for the program to behave differently depending the situation, such as specifying extra arguments used for CGI configuration. It's up to your CGI program to use the values provided by this variable.
The PATH_TRANSLATED variable is set to the absolute path to the resource represented by the URL. In the case of http://www.company.com/index.html, PATH_TRANSLATED may hold a value such as /usr/local/etc/httpd/htdocs/index.html. This allows your CGI program to be able to read this file and do something with it if necessary.
QUERY_STRING is one of the most important of all CGI environment variables. The QUERY_STRING variable is used for passing form information to a CGI. On CGIs that use the GET HTTP method, this variable will contain the query portion of the URL. Requests made to a CGI usually include a ? that is followed by the arguments to the query. In the URL http://www.company.com/cgi-bin/test?yes, the value of QUERY_STRING will be set to yes.
It is important to be aware that because QUERY_STRING is an environment variable , there are space limitations imposed by the operating system. Some systems limit the environment space anywhere from 250–8000 bytes. On my system, this limit is much larger—about 40,000 bytes. If your CGI handles a form that could potentially receive a large amount of data, you may want to consider using POST transactions to ensure portability and avoid overflows. POST transactions don't put values on QUERY_STRING; instead, the data comes into the CGI via the standard input stream.
Data in the QUERY_STRING is formatted as key=value pairs. key is the name assigned to the form widget using the NAME attribute in the HTML file. value is the value that the user assigned to the widget with a browser. Multiple key=value pairs are separated by ampersand (&) characters. In addition to this formatting, the browser will encode any non-alphanumeric character using a percent character plus the character's hexadecimal value. For example, %2C equals a , character. Spaces are encoded with a plus (+) character. The following QUERY_STRING is the result of two form fields, one called Name, the other called Address:
QUERY_STRING = Name=My+Name&Address=Some+Street+Rd.%0ACity%2C+State++12345& name=Submit
The Name field contains the data
My+Name
The space between My and Name is encoded to a +.
The Address field contains
Some Street Rd. City, State 12345
In the second field, spaces are also converted to + characters. In addition, the newline after Rd. is encoded to %0A. The %2C corresponds to a comma (,).
The REMOTE_ADDR variable contains the IP address of the host making the request. IP addresses currently are written in dotted-decimal notation (four octets or 8-bit values represented in decimal, separated by dots). If you are concerned with security (and who isn't?) it is a good idea to log this variable in a logfile created specially for this form by your CGI program. You can also log REMOTE_HOST, REMOTE_IDENT, HTTP_USER_AGENT, and HTTP_REFERER. Although this takes up disk space, it also allows you to identify people (somewhat) who submit nasty, threatening, or malicious form data. For alternative logging suggestions, please see Chapter 13, "Web Accounting."
The REMOTE_HOST variable contains the hostname of the client making the request. It will be set only if reverse DNS lookups are enabled for your server. Reverse DNS lookups create an extra load on your server and should not be enabled on high-traffic servers. If your CGI needs to determine the hostname, you should be able to determine this information easily enough when you need it with a call to /usr/bin/host (part of the BIND release), with the IP address of the host in question from the REMOTE_ADDR variable.
For clients running identd services, the REMOTE_IDENT variable will be set to the username of the user making the request. Many clients don't run this service and, as should be expected, you should never trust this information.
Requests that require user authentication will set the REMOTE_USER variable to the name the user entered during the authentication session.
The REQUEST_METHOD variable holds the name of the HTTP method used to make the request. Valid HTTP methods are GET, POST, HEAD, PUT, DELETE, LINK, and UNLINK. The Apache server implements only the first four methods, which specify where a CGI program will find its data. You can implement any of the other methods with CGI programs; however, be aware that those methods implement potential security holes. As their names suggest, PUT, DELETE, LINK, and UNLINK satisfy requests that put, delete, link, or unlink files. However, some of these methods may be very useful for implementing applications that allow a user to add information, such as adding a picture to a database.
The SCRIPT_NAME variable contains the portion of the URI that identifies the CGI running. If your URL is http://www.company.com/cgi-bin/test, SCRIPT_NAME will be set to /cgi-bin/test.
The SERVER_NAME variable holds the hostname, alias, or IP address of the server serving the request. You can use it to build self-referencing URLs. In cases where the server is configured to support virtual hosts, this variable will be set correctly to the name of the virtual host serving the request. This variable is set for all requests.
The SERVER_PORT variable contains the TCP port where the server is running. You can use the SERVER_PORT value along with the SERVER_NAME to build self-referencing URLs if your server is using a nonstandard port. The default port for an HTTP server is 80.
The SERVER_PROTOCOL variable contains the name and version of the HTTP protocol supported by the server. It has the format HTTP/version: HTTP/1.0. This value should be checked by your program to ensure that the server is compatible with your CGI program.
The SERVER_SOFTWARE variable is the equivalent of your server's info box. This variable holds the name and version of the HTTP server software serving your request. The format is name/version: APACHE/1.1. This variable is set for all requests.
In addition to the standard variables, header lines received from a browser are put into the environment preceded by HTTP_. Any dash characters (-) are changed to underscores (_).
These headers may be excluded by the server if already processed or if by including them the system's environment limit would be exceeded. Some of the most popular ones are HTTP_ACCEPT, HTTP_USER_AGENT, and HTTP_REFERER.
The HTTP_ACCEPT variable is set to the MIME types that the client browser is able to accept. You can use this information to have your CGI return richer data, such as graphics, that is acceptable by the client.
The HTTP_USER_AGENT variable is set to the name and version of the client browser in the format name/version library/version. This format string varies greatly from one browser to another. Because of the ranging capabilities of browsers, some sites provide various versions of the materials and return the one that it deems most appropriate based on information stored in this variable. This creates a situation in which some browsers do not get the "cool" version of a site. Some browser developers resolved this problem by making their wares impersonate other brands by supplying the HTTP_USER_AGENT string Mozilla (the Netscape Navigator user agent string).
Information regarding a proxy gateway is also contained here. A proxy gateway is a computer that sits between the client and the server. This proxy gateway is sometimes able to cache pages you request, reducing the amount of traffic generated from your site to that server.
The HTTP_REFERER variable holds the location the user visited that forwarded her to your site. Use of this variable may be useful to see which sites are linked to yours .
Reading environment variables in a sh is really easy—it's just like reading any other sh variable. The reason for this is that sh is the environment!
Environment variables are accessed by adding a $ before their name. To print the contents of the variable, use the echo command :
echo SERVER_SOFTWARE = $SERVER_SOFTWARE
That line will print a line that looks like this:
SERVER_SOFTWARE = Apache/1.1.1
Listing 5.4 shows a simple sh CGI based on the test-cgi script included in Apache's cgi-bin directory that prints most of the environment variables.
Listing 5.4. A simple sh CGI script .
#!/bin/sh echo Content-type: text/plain echo echo SERVER_SOFTWARE = $SERVER_SOFTWARE echo SERVER_NAME = $SERVER_NAME echo GATEWAY_INTERFACE = $GATEWAY_INTERFACE echo SERVER_PROTOCOL = $SERVER_PROTOCOL echo SERVER_PORT = $SERVER_PORT echo REQUEST_METHOD = $REQUEST_METHOD echo HTTP_ACCEPT = $HTTP_ACCEPT echo PATH_INFO = $PATH_INFO echo PATH_TRANSLATED = $PATH_TRANSLATED echo SCRIPT_NAME = $SCRIPT_NAME echo QUERY_STRING = $QUERY_STRING echo REMOTE_HOST = $REMOTE_HOST echo REMOTE_ADDR = $REMOTE_ADDR echo REMOTE_USER = $REMOTE_USER echo AUTH_TYPE = $AUTH_TYPE echo CONTENT_TYPE = $CONTENT_TYPE echo CONTENT_LENGTH = $CONTENT_LENGTH
The same CGI can be written in Perl, as shown in Listing 5.5.
Listing 5.5. The simple CGI script in Perl .
#!/usr/local/bin/perl
print "Content-type: text/plain\n\n";
print <<STOP;
SERVER_SOFTWARE = $ENV{SERVER_SOFTWARE}
SERVER_NAME = $ENV{SERVER_NAME}
GATEWAY_INTERFACE = $ENV{GATEWAY_INTERFACE}
SERVER_PROTOCOL = $ENV{SERVER_PROTOCOL}
SERVER_PORT = $ENV{SERVER_PORT}
REQUEST_METHOD = $ENV{REQUEST_METHOD}
HTTP_ACCEPT = $ENV{HTTP_ACCEPT}
PATH_INFO = $ENV{PATH_INFO}
PATH_TRANSLATED = $ENV{PATH_TRANSLATED}
SCRIPT_NAME = $ENV{SCRIPT_NAME}
QUERY_STRING = $ENV{QUERY_STRING}
REMOTE_HOST = $ENV{REMOTE_HOST}
REMOTE_ADDR = $ENV{REMOTE_ADDR}
REMOTE_USER = $ENV{REMOTE_USER}
AUTH_TYPE = $ENV{AUTH_TYPE}
CONTENT_TYPE = $ENV{CONTENT_TYPE}
STOP
The Perl program is similar to the C program, shown in Listing 5.6. The only notable difference is that the $ENV{variable_name} syntax is used to inform Perl that I am referring to an environment variable.
Listing 5.6. The simple CGI script in C .
#include <stdio.h>
#include <stdlib.h>
main (int argc, char *argv[])
{
char *p;
// Keep the server happy. Put in a Content-type header:
printf("Content-type: text/plain\n\n");
/* Most versions of printf will handle a NULL pointer as "(Null
// Pointer)" otherwise printf may crash. The solution is a macro that
// always returns something valid. The macro below tests to see if
// getenv returned something. If it returns NULL, it returns a
// "VARIABLE NOT SET" message, that should make old versions of printf
/* happy.
#define sgetenv(x) ((p = getenv(x)) ? p : "VARIABLE NOT SET")
printf("SERVER_SOFTWARE = %s\n", sgetenv("SERVER_SOFTWARE"));
printf("SERVER_NAME = %s\n", sgetenv("SERVER_NAME"));
printf("GATEWAY_INTERFACE = %s\n", sgetenv("GATEWAY_INTERFACE"));
printf("SERVER_PROTOCOL = %s\n", sgetenv("SERVER_PROTOCOL"));
printf("SERVER_PORT = %s\n", sgetenv("SERVER_PORT"));
printf("REQUEST_METHOD = %s\n", sgetenv("REQUEST_METHOD"));
printf("HTTP_ACCEPT = %s\n", sgetenv("HTTP_ACCEPT"));
printf("PATH_INFO = %s\n", sgetenv("PATH_INFO"));
printf("PATH_TRANSLATED = %s\n", sgetenv("PATH_TRANSLATED"));
printf("SCRIPT_NAME = %s\n", sgetenv("SCRIPT_NAME"));
printf("QUERY_STRING = %s\n", sgetenv("QUERY_STRING"));
printf("REMOTE_HOST = %s\n", sgetenv("REMOTE_HOST"));
printf("REMOTE_ADDR = %s\n", sgetenv("REMOTE_ADDR"));
printf("REMOTE_USER = %s\n", sgetenv("REMOTE_USER"));
printf("AUTH_TYPE = %s\n", sgetenv("AUTH_TYPE"));
printf("CONTENT_TYPE = %s\n", sgetenv("CONTENT_TYPE"));
printf("CONTENT_LENGTH = %s\n", sgetenv("CONTENT_LENGTH"));
exit(0);
}
The one notable thing occurring in this program is the use of the getenv(variable_name) function . This function returns the string stored in the environment variable matching the name of the argument provided. The following is an example:
string_pointer = getenv("HOME");
This call would return a pointer to a string describing the location of the home directory of the user running the program. If you look closely, you'll notice that I created a macro for the getenv function called sgetenv. This macro is a safeguard for users of older versions of the printf() function. If getenv returns a NULL pointer, ancient versions of printf may crash the program. My program safeguards against this condition by always returning a printable string. In this case, a NULL value will return the string VARIABLE NOT SET.
If you want to write CGI programs in C, probably the best way to write them would be to use Thomas Boutell's cgic library. This library is available from http://www.boutell.com. I have included a copy of the library on the CD-ROM for your convenience. I have written a similar Hello World! application using cgic, shown in Listing 5.7.
Listing 5.7. Hello World! in cgic .
/******************************************************************** * * HelloWorld.cgi * * This program prints out all the environment variables using Thomas * Boutell's cgic library. Make sure cgic.h is in your current dir- * ectory, and that libcgic.a is installed in the usual place (most of * the time /usr/local/lib. Please follow the cgic installation
* instructions. * *********************************************************************/ #include <stdio.h> #include "cgic.h" #define FIELD_SIZE 51 #define DEBUG 0 int cgiMain() { #if DEBUG /* Load a saved CGI scenario if we're debugging */ cgiReadEnvironment("/tmp/capcgi.dat"); #endif cgiHeaderContentType("text/html"); fprintf(cgiOut, "<HTML><HEAD>\n"); fprintf(cgiOut, "<TITLE>Hello World!</TITLE></HEAD>\n"); fprintf(cgiOut, "<BODY><H1>Hello World!</H1>\n"); fprintf(cgiOut, "cgiServerSoftware=%s<BR>\n", cgiServerSoftware); fprintf(cgiOut, "cgiServerName=%s<BR>\n", cgiServerName); fprintf(cgiOut, "cgiGatewayInterface=%s<BR>\n", cgiGatewayInterface); fprintf(cgiOut, "cgiServerProtocol=%s<BR>\n", cgiServerProtocol); fprintf(cgiOut, "cgiServerPort=%s<BR>\n", cgiServerPort); fprintf(cgiOut, "cgiRequestMethod=%s<BR>\n", cgiRequestMethod); fprintf(cgiOut, "cgiPathInfo=%s<BR>\n", cgiPathInfo); fprintf(cgiOut, "cgiPathTranslated=%s<BR>\n", cgiPathTranslated); fprintf(cgiOut, "cgiScriptName=%s<BR>\n", cgiScriptName); fprintf(cgiOut, "cgiQueryString=%s<BR>\n", cgiQueryString); fprintf(cgiOut, "cgiRemoteHost=%s<BR>\n", cgiRemoteHost); fprintf(cgiOut, "cgiRemoteAddr=%s<BR>\n", cgiRemoteAddr); fprintf(cgiOut, "cgiAuthType=%s<BR>\n", cgiAuthType); fprintf(cgiOut, "cgiRemoteUser=%s<BR>\n", cgiRemoteUser); fprintf(cgiOut, "cgiRemoteIdent=%s<BR>\n", cgiRemoteIdent); fprintf(cgiOut, "cgiContentType=%s<BR>\n", cgiContentType); fprintf(cgiOut, "cgiAccept=%s<BR>\n", cgiAccept); fprintf(cgiOut, "cgiUserAgent=%s<BR>\n", cgiUserAgent); fprintf(cgiOut, "</BODY></HTML>\n"); return 0; }
This program does not show off the true power of cgic, but you can see what's going on that's interesting.
First of all, notice that there is no main() function. Instead, cgic applications all have a cgiMain() function. Another difference is that instead of writing to stdout when you want some text to go to the browser, you write to a special file descriptor called cgiOut, defined in the cgic.h file. Where does cgiOut point? In almost every case it points to stdout. So why use cgiOut? It is mainly used to be compatible with future versions of cgic where stdout may not be where you want output to go.
You will also notice some debugging code in the program. This is a really nice feature of cgic that allows a developer to easily preserve an environment and run the CGI program with that environment from the command line or a debugger. It saves you the hassle of manually simulating the environment yourself. To use this feature you need to have the program capture compiled and located in your cgi-bin directory. Then, whenever you want to debug a cranky CGI program, just point the FORM ACTION tag to /cgi-bin/capture (make sure that capture is compiled with the default capture file set to something you want—/tmp/capcgi.dat would be good). This captures the environment and stores it in a file that can be read by using cgiReadEnvironment(). This is very useful and easier than manually running through and setting all the environment variables.
Finally, you'll notice that there are special variable names that refer to the environment variables. This is so that cgic's debugging feature will correctly write the environment to the capture file, as specified in the capture.c source code.
But cgic is much more than what you have seen. It includes functions for grabbing GET or POST form data of all types. In fact, if you're grabbing a numerical input from a form, cgic includes parameters for bounds checking. Included in the cgic documentation is an excellent HTML document that shows you exactly how to use the cgic functions.
The POST method, originally named and designated to refer to posting a message to a Usenet-like resource, is a better way to submit data from a form than GET. Unlike GET, the POST method has no restrictions on how much data can be submitted. The data from a POST submission is encoded in exactly the same way as GET; the main difference is that the string is not placed in QUERY_STRING. Instead, the string is read from stdin. How do you know when you reach the end of the string? The length is placed in the CONTENT_LENGTH environment variable. Other than these two differences, POST functions in exactly the same way as GET.
So why should you even bother with GET when POST is so much better? Well, you will use GET in the following situation: Say you want to have a text hyperlink within your HTML document to a CGI program, and you also need to pass some URL-encoded parameters to this program, such as color=red and size=large. The HTML code would be as follows:
<A HREF="/cgi-bin/somecgi.cgi?color=red&size=large">Run this</A>
The string after the ? is the URL-encoded string that is placed in QUERY_STRING as per the GET method. (You can also do a link this way with POST, but as far as I know, there is no way to make a Submit button a text link. You can make it an image by using the image tag, but for text, I don't know of a way to do it!)
Another instance where you might want to use GET over POST is when you are debugging a CGI program. You have probably faced many 500 Server Error messages when writing CGI programs. The reason for this uninformative message is security; however, that doesn't help your development efforts. The server swallows sterr and doesn't redirect it to anywhere useful. If you run the CGI program from the prompt, you will see the error messages and explanations generated by the CGI program that make debugging easier. (Thomas Boutell's cgic library provides a much nicer way of debugging CGI programs. Read on to find out more!)
CGI is nothing more than a set of environment variables. You can manually simulate a GET request in the following way:
% setenv 'REQUEST_METHOD' 'GET' % setenv 'QUERY_STRING' 'color=red&size=large' % somecgi.cgi [results]
These commands assume that you are using csh, of course. If you are using the Bourne shell (sh), declare environment variables as follows:
% REQUEST_METHOD=GET % QUERY_STRING="color=red&size=large" % export REQUEST_METHOD % export QUERY_STRING % somecgi.cgi [results]
Just set the environment variables yourself and run the CGI program from the prompt. Can you do the same thing with POST? After all, POST is done virtually the same way except for stdin. Well, this is what you'd have to do:
% setenv 'REQUEST_METHOD' 'POST' % setenv 'CONTENT_LENGTH' '20' % somecgi.cgi (waiting for input) color=red&size=large % [results]
Aha! There's the gotcha! CONTENT_LENGTH needs to be set to the number of characters to read from stdin. Can you imagine what a pain it would be to have to count the number of characters each time you have a different form string? GET is much easier for debugging purposes. Use it until you are sure everything works; then make your form submit data via POST. (Or, if you are using C, use Boutell's cgic library debugging functions.)
As I've mentioned, most of the time CGI programs don't receive their information from the stdin stream. The POST method should be used for anything that has more than a few small input fields to avoid any problems with running out of space on the environment space.
However, requests of the type POST (or PUT) do put information after the header. Under these requests, some data will be sent to your program through stdin, which you need to read. However, unlike traditional UNIX programs, the HTTP server is not obligated to send an EOF (end of file) following CONTENT_LENGTH bytes of data. This means that you need to determine the amount of data that you are able to read beforehand. Luckily, the server will set the CONTENT_LENGTH variable to the amount of data you can safely read from stdin.
Data sent through stdin is encoded in the same way as values passed through QUERY_STRING .
Output from your CGI program usually goes to stdout. This information can be raw HTML or some other MIME type that your program creates, or instructions to the client to retrieve the output (a redirection). The previous sample programs have been returning either text/plain or text/html MIME formats. When returning text/html, you need to make sure that the HTML you return is the correct HTML.
In addition, any content you return must be preceded by one of the following headers and two new lines.
If you are returning content generated from within your CGI, you'll need to set the content-type header to the MIME type of the data you are returning, typically this will be HTML or plain text. For example, CGIs that return text should set the content header like this:
Content-type: text\plain
CGIs that return HTML-formatted text should return a content header like the following:
Content-type: text\html
Instead of returning data, you can use this header to specify that you are returning a reference or redirection instead of the actual document. When this header is set to a URL, the client will issue the redirect; the client (browser) is then responsible to fetch the document. If set to a virtual path, the server will intercept it and return the document listed:
Location: http://www.somewhere.com
When the server receives this header from a CGI, it will try to point the client browser to the http://www.somewhere.com URL.
This is the result code returned to the client. It is composed of a three-digit code and a string describing the error or condition .
The most basic thing you will ever do is collect data from an user and then process that data in some way. This will involve the use of HTML forms. Forms are a series of user-interface items that allow the user to set values: text fields, text boxes, radio buttons, check boxes, pop-up menus, and so on. Your HTML code is responsible for drawing these items and assigning them a name. A sample form looks like this in code:
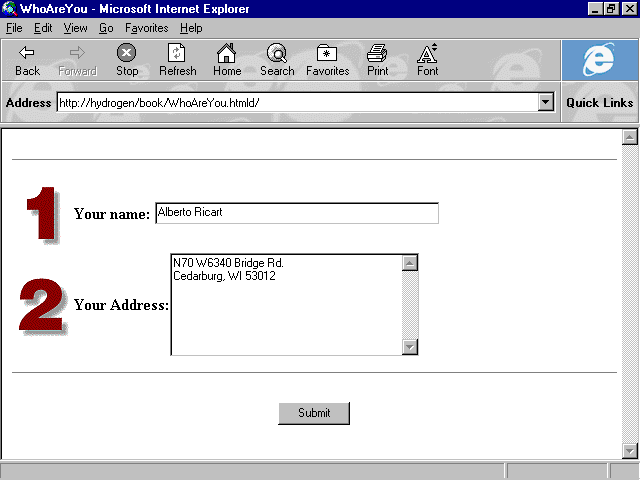
<HTML> <HEAD> <TITLE>WhoAreYou</TITLE> </HEAD> <BODY BGCOLOR="#ffffff"> <FORM ACTION="/cgi-bin/printenv" ENCTYPE="x-www-form-encoded" METHOD="GET"> <HR> <IMG SRC="1.gif" WIDTH="57" HEIGHT="77" ALIGN="MIDDLE"> <STRONG>Your name: </STRONG> <INPUT NAME="Name" TYPE="text" SIZE="53"><BR> <IMG SRC="2.gif" WIDTH="57" HEIGHT="77" ALIGN="MIDDLE"> <STRONG>Your Address: </STRONG> <TEXTAREA NAME="Address" ROWS="6" COLS="50"></TEXTAREA> <BR> <HR> <P><CENTER><INPUT NAME="name" TYPE="submit" VALUE="Submit"></CENTER> </FORM> </BODY> </HTML>
This code produces a form that looks like Figure 5.1, when viewed under Microsoft's Internet Explorer version 3.
Figure 5.2. A simple form viewed with Microsoft's Internet Explorer version 3.
You can create forms by just typing the specifications, but sometimes it's a lot easier to use a graphical tool . Graphical tools allow you to lay out the form in an attractive and useful way. I like creating the basic form template in a program called Adobe PageMill. PageMill is an easy-to-use program for the Macintosh that generates HTML pages.
When you submit this form, your browser will return something similar to the following:
SERVER_SOFTWARE = Apache/1.1.1 GATEWAY_INTERFACE = CGI/1.1 DOCUMENT_ROOT = /NextLibrary/WebServer/htdocs REMOTE_ADDR = 204.95.222.3 SERVER_PROTOCOL = HTTP/1.0 REQUEST_METHOD = GET REMOTE_HOST = lithium HTTP_REFERER = http://hydrogen/book/WhoAreYou.htmld/ QUERY_STRING = Name=Alberto+Ricart&Address=N70+W6340+Bridge+Rd. %0D%0ACedarburg%2C+WI++53012&name=Submit HTTP_USER_AGENT = Mozilla/2.0 (compatible; MSIE 3.0B; Windows 95;640,480 HTTP_ACCEPT = */* HTTP_ACCEPT_LANGUAGE = en SCRIPT_NAME = /cgi-bin/printenv SCRIPT_FILENAME = /NextLibrary/WebServer/apache/cgi-bin/printenv HTTP_PRAGMA = no-cache SERVER_NAME = localhost SERVER_PORT = 80 HTTP_HOST = hydrogen SERVER_ADMIN = webmaster@ACCESSLINK.COM
As you can imagine, before you can do anything useful with the QUERY_STRING you'll need to decode it. After you have decoded all encoded characters, you'll need to split them into key and value pairs.
The effort required to do this will depend on what you are using to develop a CGI. If you are using sh, you will run into some difficulties. You'll probably have to use an awk and sed script to preprocess your data; too much work! However, don't despair. Just because it's hard doesn't mean that someone didn't already go through these pains.
Steven Grimm has developed a package called Un-CGI that takes the hard work of decoding your program input. Un-CGI decodes the form input and places the decoded information in the environment as environment variables, which are very easy to access from a shell. I have reprinted Grimm's Un-CGI documentation in Appendix A, "Un-CGI Version 1.7 Documentation." Un-CGI makes it possible to write CGI using the sh or csh easily.
C will present you with similar challenges. You'll have to write a few decoding routines as well as a routine to split the data into simple key/value pairs that you can access, or you'll have to use Thomas Boutell's uncgic library
Perl, by far, provides the easiest way of dealing with the decoding and conversion of the data into variables that you can access easily .
Perhaps the most frequently asked question on all of the HTML and CGI newsgroups is "How do I e-mail the contents of a form to myself?" The answer is contained in the following program listings. The first listing is a group of useful functions I wrote for developing CGI programs. It is a Perl package and must be imported into a program via the following statement:
require CGILIB;
Then, whenever you want to use a function in the library, first of all, make sure that CGILIB.pm is in the same directory or that it is in your @INC path. One function in CGILIB.pm is responsible for decoding the input string. This is the function parse_form(). It returns an associative array with all of the form keys and values. When you have this array, you can do anything with it that you want. In this case, you want to simply mail the contents of the array back to yourself.
The second listing is the actual Perl mailing program. It takes the user input values from an HTML form and mails the results to the address specified in the recipient field of the HTML form. It extracts some other various useful information for the e-mail response as well, such as client browser information, the date submitted, and information about the location from which the sender is submitting. This is all very relevant material, especially for simple security precautions.
To use this humble program, just install the programs in Listings 5.8 and 5.9 in your cgi-bin directory and create a form whose ACTION target is cgi-bin/mail.cgi. Listing 5.10 is a sample form so you can see how it is done.
Listing 5.8. CGILIB.pm .
package CGILIB;
################################################################
# Print the content-type header.
#
# &print_header;
sub print_header
{
print "Content-type: text/html\n\n";
}
################################################################
# Print a canned header with title as argument.
#
#
sub canned_header
{
my( $title ) = @_;
print "<HTML>\n";
print "<HEAD>\n";
print "<TITLE>$title</TITLE>\n";
print "</HEAD>\n";
}
################################################################
# Print the closing lines for an HTML document.
#
# &print_closing;
sub print_closing
{
print "</BODY></HTML>\n";
}
################################################################
# Parse the HTML header and form
# information
#
# %ASSOC_ARRAY = &parse_form;
sub parse_form
{
my ($buffer,$name,$value,%FORM);
my ($content_length,$query_string,$request_method);
$content_length = $ENV{'CONTENT_LENGTH'};
$query_string = $ENV{'QUERY_STRING'};
$request_method = $ENV{'REQUEST_METHOD'};
# If the REQUEST_METHOD was POST, read from stdin, else the string is in QUERY_STRING
if ($request_method eq 'POST') {
read(STDIN, $buffer, $content_length);
}
else {
$buffer = $query_string;
}
# Split the name-value pairs
@pairs = split(/&/, $buffer);
foreach $pair (@pairs)
{
($name, $value) = split(/=/, $pair);
# Un-Webify plus signs and %-encoding
$name =~ tr/+/ /;
$value =~ tr/+/ /;
$value =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
$name =~ s/%([a-fA-F0-9][a-fA-F0-9])/pack("C", hex($1))/eg;
# Stop people from using subshells to execute commands
# Not a big deal when using sendmail, but very important
# when using UCB mail (aka mailx).
$value =~ s/~!/ ~!/g;
# Uncomment for debugging purposes
# print "Setting $name to $value<P>\n";
$FORM{$name} = $value;
}
%FORM; # Returns %FORM to caller source...
} #End Sub form_mail
###########################################################################
#
# sub dump_env_vars
#
# Dumps the contents of %ENV in HTML
#
# INPUTS: \%ENV
#
###########################################################################
sub dump_env_vars
{
my ($ENV) = @_;
foreach (keys %$ENV)
{
print "$_=$$ENV{$_}<BR>";
}
}
# For require files
1;
Listing 5.9. mail.cgi .
#!/usr/local/bin/perl -w
#
# mail.cgi: This is an CGI program that sends the results of the fill-out
# form to the recipient indicated in the form.
#
# Note: This CGI program relies on hidden variables in the form associated
# with this listing.
require CGILIB; #Use the lib included in book
use strict; #Make sure we declare all our variables
$| = 1; #Flush STDOUT
my( %FORM ); #Declare all the variables
my( $recipient, $sender, $thank_you );
my( $mailprog );
%FORM = CGILIB::parse_form();
$mailprog = '/usr/lib/sendmail';
# Location of thank_you page to be displayed after submitting form
$thank_you = $FORM{thank_you_location};
$recipient = $FORM{recipient};
$sender = $FORM{email};
#Grab some environment info
$FORM{Date} = `date`;
$FORM{ServerProtocol} = $ENV{'SERVER_PROTOCOL'};
$FORM{RemoteHost} = $ENV{'REMOTE_HOST'};
$FORM{RemoteAddress} = $ENV{'REMOTE_ADDR'};
$FORM{HTTPUserAgent} = $ENV{'HTTP_USER_AGENT'};
email_recipient();
say_thank_you();
exit(0);
########################################################################
#
# email_recipient() : calls the mail program and sends a message.
#
sub email_recipient
{
my( $key );
open (MAIL, "|$mailprog $recipient") || die "Cant open mail program: $!";
print MAIL "To: $recipient\n";
print MAIL "From: $sender ($FORM{name})\n";
print MAIL "Reply-To: $sender ($FORM{name})\n";
print MAIL "Subject: Email from Web Form :) \n\n"; #Need two \n's for
foreach ( keys %FORM )
{
print MAIL "$_ : $FORM{$_}\n";
}
print MAIL "\n\n End of email message.\n";
close( MAIL );
}
########################################################################
#
# say_thank_you() : redirects user to the thank-you page.
#
sub say_thank_you
{
print "location: $thank_you\n\n";
}
Listing 5.10. form.html .
<HTML> <HEAD> <TITLE>My Cool Email Form</TITLE> </HEAD> <BODY> <FORM METHOD="GET" ACTION="mail.cgi"> <INPUT NAME="recipient" TYPE="hidden" VALUE="youremail@yourdomain.com"> <INPUT NAME="thank_you_location" TYPE="hidden" VALUE="http://www.yourdomain.com/ thank_you.html"> <P> <STRONG>Name:</STRONG><BR> <INPUT NAME="name" TYPE="text" SIZE=40> </P> <P> <STRONG>Email:</STRONG><BR> <INPUT NAME="email" TYPE="text" SIZE=40> </P> <P> <STRONG>Comments:</STRONG></BR> <TEXTAREA NAME="comments" COLS=40 ROWS=10></TEXTAREA> </P> <INPUT TYPE="submit"> </FORM> </BODY> </HTML>
As you can see, I have included an example form. You may be wondering about the thank_you.html URL in the variable thank_you_location. Well, you have to create it. It is what your page visitors will see after they submit their form to the mail.cgi program. The process used is called redirection. A location header followed by two newline characters is sent, which redirects the user to the desired page.
The next program listing e-mails form results like the others, but uses Thomas Boutell's cgic library. Also, the form (shown in Listing 5.11) used is slightly different.
Listing 5.11. The form in cgic .
/**********************************************************************
*
* email.cgi:
*
* This program reads the fields of the given form and emails
* the contents to the destination, kept in the hidden field from within
* the form. The program uses Thomas Boutell cgic library.
*
**********************************************************************/
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include "cgic.h"
#define FIELD_SIZE 51
#define ADDRESS_SIZE 500
#define DEBUG1 0
#define TO "webmaster@foo.bar.com" /* Substitute your address */
#define FROM "Web Fill-Out Form"
void printEnvironmentVariables();
int cgiMain()
{
char name[FIELD_SIZE];
char address[ADDRESS_SIZE];
FILE* mailer;
#if DEBUG1
/* Load a saved CGI scenario if we're debugging */
cgiReadEnvironment("/tmp/capcgi.dat");
#endif
cgiFormStringNoNewlines( "Name", name, FIELD_SIZE);
cgiFormString( "Address", address, ADDRESS_SIZE);
/* Open a pipe to sendmail */
mailer = popen( "/usr/lib/sendmail -t", "w" );
if (mailer <= 0)
{
perror( "Unable to open pipe to sendmail\n" );
exit( 1 );
}
#if DEBUG
printf( "popen: Done\n" );
#endif
/* Now fill in the sendmail headers */
fprintf( mailer, "To: " TO "\n" );
fprintf( mailer, "From: " FROM "\n" );
#if DEBUG
printf( "From: Done\n" );
#endif
fprintf( mailer, "Subject: Results of fill-out form for %s\n\n", name );
/* Now give the results of the form */
fprintf( mailer, "Name: %s\n", name );
fprintf( mailer, "Address: \n%s\n", address );
fprintf( mailer, "\nEnd of form submission.\n" );
pclose( mailer );
cgiHeaderContentType("text/html");
fprintf(cgiOut, "<HTML><HEAD>\n");
fprintf(cgiOut, "<TITLE>Form Mailed!</TITLE></HEAD>\n");
fprintf(cgiOut, "<BODY><H1>Form Mailed!</H1>\n");
fprintf(cgiOut, "Thank you, %s. Your email will be read ASAP!<BR>\n",
name );
printEnvironmentVariables();
fprintf(cgiOut, "</BODY></HTML>\n" );
return 0;
}
void printEnvironmentVariables()
{
fprintf(cgiOut, "cgiServerSoftware=%s<BR>\n", cgiServerSoftware);
fprintf(cgiOut, "cgiServerName=%s<BR>\n", cgiServerName);
fprintf(cgiOut, "cgiGatewayInterface=%s<BR>\n", cgiGatewayInterface);
fprintf(cgiOut, "cgiServerProtocol=%s<BR>\n", cgiServerProtocol);
fprintf(cgiOut, "cgiServerPort=%s<BR>\n", cgiServerPort);
fprintf(cgiOut, "cgiRequestMethod=%s<BR>\n", cgiRequestMethod);
fprintf(cgiOut, "cgiPathInfo=%s<BR>\n", cgiPathInfo);
fprintf(cgiOut, "cgiPathTranslated=%s<BR>\n", cgiPathTranslated);
fprintf(cgiOut, "cgiScriptName=%s<BR>\n", cgiScriptName);
fprintf(cgiOut, "cgiQueryString=%s<BR>\n", cgiQueryString);
fprintf(cgiOut, "cgiRemoteHost=%s<BR>\n", cgiRemoteHost);
fprintf(cgiOut, "cgiRemoteAddr=%s<BR>\n", cgiRemoteAddr);
fprintf(cgiOut, "cgiAuthType=%s<BR>\n", cgiAuthType);
fprintf(cgiOut, "cgiRemoteUser=%s<BR>\n", cgiRemoteUser);
fprintf(cgiOut, "cgiRemoteIdent=%s<BR>\n", cgiRemoteIdent);
fprintf(cgiOut, "cgiContentType=%s<BR>\n", cgiContentType);
fprintf(cgiOut, "cgiAccept=%s<BR>\n", cgiAccept);
fprintf(cgiOut, "cgiUserAgent=%s<BR>\n", cgiUserAgent);
}
The associated HTML code for the form is shown in Listing 5.12.
Listing 5.12. The new HTML code .
<HTML> <HEAD> <TITLE>WhoAreYou</TITLE> </HEAD> <BODY BGCOLOR="#ffffff"> <FORM ACTION="/cgi-bin/email.cgi" ENCTYPE="x-www-form-encoded" METHOD="GET"> <HR> <IMG SRC="1.gif" WIDTH="57" HEIGHT="77" ALIGN="MIDDLE" SIZE=50> <STRONG>Your name:</STRONG> <INPUT NAME="Name" TYPE="text" SIZE="53"><BR> <IMG SRC="2.gif" WIDTH="57" HEIGHT="77" ALIGN="MIDDLE"> <STRONG>Your Address:</STRONG> <TEXTAREA NAME="Address" ROWS="6" COLS="50"></TEXTAREA><BR> <HR> <BR> <P ALIGN=CENTER> <INPUT NAME="name" TYPE="submit" VALUE="Submit"> </P> </FORM> </BODY> </HTML>
As you can see from the C code, the only thing really different about calling sendmail using C is that you use the popen() system call within the unistd.h header file. This system call is actually also what Perl uses internally when you do an open() to a pipe.
They say variety is the spice of life. Well, if that's true, then it is the lifeblood of any good Web site. People will be certainly more inclined to come back to your Web site if the information and look of your site changes over time. The problem with keeping your site fresh and different is that it requires a lot of maintenance if you code it statically—that is, you have to manually enter changes into one or more HTML files for display.
Randomizer programs can add a little variety to your Web site without a lot of tedious work. The two I discuss here are an image randomizer and a URL randomizer.
One good way to do this is through the use of an image randomizer program. Wouldn't it be nice if every time a user loaded one of your pages, he or she would see a different image depending on the context of the page?
Or perhaps you're the enterprising type and you want to get into the advertising business. You could statically display banners on each page, but that wouldn't be very flexible. You'd have to charge more for the most frequently hit pages, less accordingly for the lesser-hit pages, and most importantly, you'd have to manually rotate the image tags if you wanted a rotating display schedule! Well, what if you could guarantee an advertiser exposure on every page—say 1 in every 10 hits? Much more attractive to the advertiser and easier on your time.
I have created such a beast for inclusion with this book, shown in Listing 5.13. The image randomizer displays a random image from a configuration file with each hit on the page. Varying the frequency of each individual banner URL in the config file increases the chances of seeing that particular banner, thus allowing for rate schedules for advertisers wanting more exposure. The beauty of this scheme is that you can mix it with a static banner display scheme. Say, for example, one company wants to pay you a ton of money for placing its banner on your front page all the time. Well, that's fine; just statically code the URL. Done! The randomizer runs only when you tell it to. It doesn't have to be used on each page.
This program is written in Perl and must be run on a server with server-side includes enabled (see Chapter 6, "SSI—Server-Side Includes"). Also, you need to specify a configuration file, which is a file consisting one or more lines of the following format:
"Link-URL","Image-URL","IMAGE_OPTIONS"
Briefly, "Link-URL" specifies a fully qualified URL for the destination the user is taken to upon clicking the banner, "Image-URL" is a fully qualified URL for the banner itself, and "IMAGE_OPTIONS" is a tag added to the <IMAGE> tag of the banner graphic. Any string of valid tags and values is acceptable here, the most important, perhaps, being the "BORDER=" tag, which is a Netscape extension to HTML specifying the size and presence of a hyperlink color border around an image.
So a sample graphics.conf would look something like this:
"http://www.foobar.com","http://www.yoursite.com/banners/foobar.gif","BORDER=0" "http://www.anothersite.com","http://www.yoursite.com/banners/anothersite.gif", "BORDER=0" "http://www.foobar.com","http://www.yoursite.com/banners/foobar.gif","BORDER=0" "http://www.foobar.com","http://www.yoursite.com/banners/foobar.gif","BORDER=0"
In this configuration file, there are only two advertisers who have banners. However, foobar.gif will be seen 75 percent of the time (3 out of 4), while anothersite.gif will be seen 25 percent of the time (1 out of 4). This allows for a schedule of rates, as I mentioned.
Listing 5.13. The Perl randomizer .
#!/usr/local/bin/perl -w # # random.cgi - prints a graphic at random from a configuration file # # $conf_file: the absolute path to your configuration file (your listing of # URL's to the graphics. # # $ad_tag: the string outputted to the web page SSI location # # Call this script from a server-parsed html document (.shtml for example) and make # sure that server-side includes are enabled. # # Use the following example code: # # <!--#exec cmd="/yourpath/random.cgi"--> # # Of course, substitute your actual path to the random.cgi for / yourpath. Again, # this won't work unless Server-Side Includes are activated for Apache... use strict; # Declare all our variables before using them $| = 1; # Flush the output buffer #Variables my( $conf_file, $URL, $graphic, $ad_tag, $border ); my( @Graphics ); my( $num_graphics, $rand_graphic ); $conf_file = "/path-to-config-file/graphics.conf"; srand; open( IN, $conf_file ) || die "Cannot open $conf_file: $!"; @Graphics = <IN>; close( IN ); $num_graphics = @Graphics; #Get length of @Graphics array $rand_graphic = int( rand( $num_graphics - 1 ) ); ($URL,$graphic,$border) = split( /,/, $Graphics[$rand_graphic] ); $URL =~ s/\"//g; $graphic =~ s/\"//g; $border =~ s/\"//g; $ad_tag = "<A HREF=\"$URL\"><IMG SRC=\"$graphic\" $border></A>"; print $ad_tag; exit( 0 );
You can very easily adapt the image randomizer to act as a URL randomizer . What good is a URL randomizer? Well, it adds that ever-so-important quality of variety to your site, and it allows you to direct people to random, but related sites of interest.
Say you were writing a page about turtles—their habitats, behavior, variations, basically the whole "turtle thing." Being the thorough person you are, you decide to include hyperlinks to those resources in your page. Naturally, there are a lot of resources on turtles on the Internet. Yahoo! lists 31 entries on the query turtle—too many to include on a main page. So you decide to include the hyperlinks on a separate page called "Turtle Links." But this is away from the main page; you need something more eye-catching to draw people to other resources. Aha! Perhaps a "Link of the Day" at the top of your main page would look cool.
How could you use the image randomizer to do this? Well, the easiest way to do it is to simply create one image for "Random Turtle Link of the Day" and make it the default clickable image for each hyperlink in the graphics.conf file. No modifications are necessary.
Another useful application a bulletin board , or message board. This provides a way for a user of your Web site to not only give feedback on various topics, but to see other people's opinions and ideas.
The program I have provided to illustrate this concept is very simple. (See Listing 5.14.) It provides a framework to which you can add the features you need. In its current working form, a user can add a message, clear the board of messages, or update the board to see new messages. Obviously, you don't want to give the user the capability to clear the board, and maybe you don't want her to be able to directly modify the message board file by posting the message to the message board without your review. You can make modifications to avoid this—for example, have all messages mailed to your address for review and censorship. Then, if a message is appropriate, you could post it to the board. This would solve all sorts of problems, such as people not conforming to the general theme of the board.
Another use of the board is as a chat vehicle. Two or more people could be given the address of the board, and then through the use of the Add and Update buttons, a "conversation" could be held. This is very useful if you want to have a conference call of more than two people, because IRC and talk are not options for everyone.
The program is written in Perl, as you can see from the source code, and it requires the CGILIB.pm library listed in Listing 5.8.
Listing 5.14. The Perl bulletin board .
#!/usr/local/bin/perl -w
#
# board.cgi
#
# This program writes messages to a message board.
#
unshift (@INC,"/NextLibrary/WebServer/htdocs/perl/lib");
use strict;
require CGILIB;
# Parse the form data
my(%FORM) = CGILIB::parse_form();
# The location of the messageboard file. This should be something
# other than /tmp if you want the messages to hang around in case
# your system goes down. However, /tmp is fine if all you want is
# a chat session.
my($board_file) = "/tmp/messageboard";
# Add a message
if ( $FORM{action} =~ /add/ )
{
# Add message only if message body isn't empty
if ( $FORM{message} ne "" )
{
add_message();
}
}
# Clear the board of messages.
elsif ( $FORM{action} =~ /clear/ )
{
system( "rm $board_file" );
}
# Default actions
display_form();
display_board();
exit(0);
##################################################################
#
# sub display_form()
#
# Prints out the header and the HTML for the form part of the page.
#
sub display_form
{
CGILIB::print_header();
print <<STOP;
<HTML>
<HEAD>
<TITLE>Message Board</TITLE>
</HEAD>
<BODY>
<H1>Message Board</H1>
<FORM METHOD="GET" ACTION="board.cgi">
<TEXTAREA NAME="message" ROWS=10 COLS=40 WRAP=VIRTUAL></TEXTAREA>
<BR>
<INPUT NAME="action" TYPE="submit" VALUE="add">
<INPUT NAME="action" TYPE="submit" VALUE="clear">
<INPUT NAME="action" TYPE="submit" VALUE="update">
</FORM>
<HR>
STOP
}
##################################################################
#
# sub display_board()
#
# Displays each message, in the order of most recent to least recent.
#
sub display_board
{
my( @board );
my( $count ) = 0;
my( $message );
# Check to see if messageboard file exists.
if (-e $board_file)
{
# Load message file and slurp all the messages into an array.
# One message per line. Newline is the delineator.
open( BOARD, $board_file ) || die "Cannot read $board_file: $_";
@board = <BOARD>;
close( BOARD );
# Since messages are appended to the end of the file, simply
# reversing the array will order them in most-recent-first.
@board = reverse( @board );
# Now traverse the array, printing each message
foreach $message (@board)
{
$count++;
print "<STRONG>Message $count:</STRONG>\n";
print "<BLOCKQUOTE>$message\n";
print "</BLOCKQUOTE><BR>\n";
}
}
# Else message board is empty
else
{
print "<EM>Message Board empty</EM>\n";
}
print "</BODY></HTML>\n";
}
##################################################################
#
# sub add_message()
#
# Appends a message to the end of the messageboard file. Converts
# all newlines to <BR> tags for convenient processing.
#
sub add_message
{
my( $message );
# Open messageboard file for appending.
open( BOARD, ">>$board_file" ) || die "Cannot write $board_file: $_";
$message = $FORM{message};
# Convert newlines (\n) to <BR>
$message =~ s/\n/<BR>/g;
print BOARD "$message\n";
close( BOARD );
}
CGI is a very complex topic and one that is important for most Web applications. Instead of reinventing the wheel (that is, unless you think you can do it better), there are tons of tools out on the Net such as cgic and Un-CGI that can make your life much easier. Instead of reinventing, search. More than likely someone has already done what you are looking for.
While this chapter has discussed the generalities of how to write a CGI program, it didn't address any of the issues you need to address when writing a secure CGI program. Before you write your first CGI program intended for public consumption, you may want to read Chapter 16, "Web Server Security Issues." The information there may be very enlightening.
If your site is CGI intensive (you run many CGI programs), you may benefit from learning about FastCGI. FastCGI is a replacement for the CGI mechanism that offers incredible performance gains with very little modification to what you have learned in this chapter. Information about FastCGI is covered in great detail in Appendix C, "FastCGI."
![]()
![]()
![]()
![]()
{kind=link}
{kind=link}