![]()
![]()
![]()
Before you build your Web site, you may want to consider its organization. While more than likely you have thought of many ways of organizing your Web site's structure, you have probably thought about it from a navigational perspective. In addition to thinking about it from that angle, I would suggest that you also think about your Web site's structure from a maintenance point of view. What can you do to make your Web site easier to maintain? What conventions will simplify the structure of your pages?
The result of this early structuring process will help you set a standard to guide your efforts. Now that you have your server up and running, it would be a good opportunity to consider a few of the issues involved. By no means, is this the only approach that you can use. Any thought-out logical system should serve you equally well. Many of the ideas presented here are used at accessLINK, inc., a small Web presence provider where I spend many hours of my day. AccessLINK develops several small- to medium-sized Web sites per week and maintains a few more on a daily basis. This chapter presents some of the ideas that I use for organizing our work. I will also address some other services, such as automatic support for personal Web pages, that your users will want you to implement.
Organizing your Web site is not about structuring a Web site so that visitors can find their way around. It's something you do for yourself; it's your filing mechanism. If you follow a few basic guidelines, the maintenance of your Web site will be much easier. Upgrading to new versions of the software will be a snap, and other administrative chores such as backups will require less time and effort.
AccessLINK's servers are closely guarded because they all have close control what goes into the servers. We don't have end users setting up their own sites or writing their own programs. Because of this, accessLINK's needs are bound to be a little different from yours, but many of their structuring methodologies will help you build a better site. They are a Web presence provider. Simply put, they'll put your company on the Web. Their services range from designing and building a site, to hosting your site on one of their servers, all while maintaining the same look and feel you would have if you had a Web server running in your own network. They handle all the issues a company faces when it first gets on the Net.
When you are building a site in-house, the responsibility for building and maintaining it will fall in the hands of the System Administrator. System Administrators are usually overworked, and to add to their responsibilities, the managing of a Web site of any size may be beyond some organization's means or policy. When possible, it is fair to say, the better prepared you are to maintain the site, the less bumpy the entire process will be. You should take it as a rule that unless you have a static Web site—one that won't change very often—development accounts for less than a third of the effort. Maintenance and future modifications comprise the real bulk of time.
Addressing security concerns is a very time-consuming task (not to mention costly). I find that many customers just want to get online and have someone else deal with the associated security problems. Security is the number one concern, and it should be because there's a lot to worry about. Setting up a Web site is like opening a window into your network. Many people will be very happy to window-shop. Others will try to snoop to see what they can find, and still others will try to force the window open. Scary.
Security concerns for a small to medium organization are not addressable in hours, and the costs associated are not small. Privacy of information and peace of mind are important. Just think about all the information that is stored on your systems. What sort of problems would you have if these records ended up in the wrong hands? What would happen if a vandal destroyed or corrupted your data?
To think about the security implications, without combining it with the pressure to be published on the Internet, is a good thing. Most organizations should not even consider going on the Internet unless they have implemented some sort of network security, such as a firewall. If you have pressure, go find a Web server provider to host your site while you resolve the security issues. An Internet Service Provider (ISP) is already set up to address these problems. Once you have figured out the implications and you are ready, they will be happy to help you migrate your Web site in-house.
I believe that organization starts in UNIX. If your system is not well organized or you have not followed a consistent method, you may want to consider why this is a good idea. Many new administrators take simple organizational methodologies, such as the location of added software, for granted. A few months later the result is that changes, such as upgrades, require additional time to install and troubleshoot. In the end, you may save a considerable amount of time by doing three very simple things:
These won't make any sense unless you commit to them for the long haul. Spending a lot of time setting up an organizational scheme won't work unless you're able to do it. If you find that you cannot organize when you have a deadline, simplify what you pick and make it a part of our life.
What is local software? Local software is local. It's not part of your original system distribution. It's the software that you've added. This is software that will need to survive future upgrades. Installation of your Web server software is a good example. You should store it in a way that makes it easy for you to upgrade both your operating system software and the software you have added.
Many software upgrades will replace, without impunity, programs that they find in the standard UNIX directories, such as bin, etc, and usr. If your modifications are to survive operating system upgrades, you'll need to find a place where these programs can happily coexist.
A good place is in the /usr/local tree. This directory can be the entry point for programs that you add. A good model to follow is to mirror your UNIX software like this:
bin
etc
lib
man
named
ftp
etc
Minerva
Put all binaries that you add in /usr/local/bin. This makes it easy for users to find and easy for you to maintain. If you upgrade a program to a new version, which is also included in your operating system release, keep the original in its place. Set /usr/local/bin in your path, ahead of the other system directories. You can do this by adding an entry to your PATH environment variable. Where this is done depends on the shell you are using. Typically, this will be in the .profile or .cshrc files in your home directory. Note that these files start with a period, so they normally will be hidden from view.
In the .profile file, the new path addition will look like this:
PATH=/usr/local/bin:/usr/ucb:/bin/...
Note that the paths to the directories that search for executables are separated by colons. Directories listed first are searched first.
If you are using the csh (c shell), you will want to put an entry into your .cshrc file. This is the same as your .profile entry, but the csh syntax for defining the environment variables is a little different:
set PATH=(/usr/local/bin /usr/ucb /bin ...)
Under the csh, multiple paths are separated by spaces and grouped together with parentheses.
Other directories, such as /usr/local/etc, contain the Web server tree. Storing it in its default place removes one source of potential problems. By keeping the default installation location, future upgrades will find the files in their standard locations. Moving default installation locations without having a really good reason for the change is asking for trouble. Future upgrades won't work properly because they will not be able to find supporting files, and you will be required to spend time hunting for the problem.
Having a written organizational policy will help cast in stone the structure of your site. If everyone decides on their own where to place files, you'll end up with a mess. Software will be installed and configured wherever someone felt that the files should go. Perhaps, they were installed on top of your system's distribution—a practice that often spells disaster if later you find out there's a bug, and the version that came with your operating system worked better!
An organizational scheme permits you to easily back up software you have added. If you need to install an additional machine and want to upgrade some of your customizations, the process is simplified and becomes really easy. All you need to do is copy the /usr/local tree, and everything is there. From that point, you can either opt to remove software you won't need or just keep it. The UNIX rdist command can be very helpful in maintaining multiple identically configured systems in sync.
Should you ever need a backup, a quick tar -cf /tmp/usrlocal.tar /usr/local will take care of the problem. You don't need to differentiate or select from various places that may contain files you added. It's all kept together.
The concept of page wrapper was developed at accessLINK. A page wrapper is no more than a directory that keeps all relevant resources (images or additional HTML files) grouped together in a bundle. The concept is hierarchical, so ideally you would group a section of multiple page wrappers together into a section.
Grouping HTML files into a page.htmld directory is a good way of keeping tabs on files (we group root trees in a sitename.ws wrapper; ws stands for Web site).
My experience has been that if I create a directory that contains all the necessary resources for an HTML document and group it all in a wrapper, it becomes easy for me to maintain that page. The system also enhances the recycling of disk space. If you are working on a HTML file and you remove a reference to an image that is stored in a different directory, it's likely to remain there. If it is near your HTML file, more than likely the file will be discarded, freeing disk space for other things.
This organizational scheme works best when several people are responsible for keeping a site running. When a document needs to be updated, the location of all the related resources are stored together and nicely packaged. The alternative is chaos. In a normal scenario where forty HTML files are stored at the same directory level along with associated resources (such as images or videos), it becomes impossible to determine what needs to be done. To figure out referenced images in a file, you have to look at the HTML code and search for the tags for the image filename. With the wrapper, much of the chaos is removed and the structure is simplified. By simple inspection of the directory's contents, you can find what you are looking for.
It's no miracle that this basic structure also happens to follow the physical structure of the site. The directory structure mirrors the navigational structure, providing another level of reinforcing the way the site is organized for people who update and manage this site. Just by navigating it, you have an understanding of the physical layout of a site.
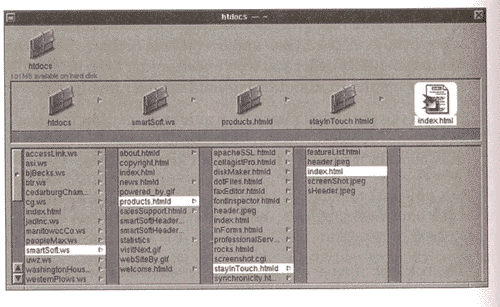
Figure 3.1. The Web site directory hierarchy. All references are localized. Global items are placed at the top. Local items only used on a particular page remain close to their resources. The window capture shows the directory tree from htdocs downward and describes the file organization scheme.
Figure 3.1 is a visual representation of the system. The htdocs tree contains a series of wrappers with a ws extension, which stands for Web site. Each of the sites listed lives in one of accessLINK's servers. One of them is for SmartSoft, Inc., a software development company. All files related to the SmartSoft site are stored inside the smartSoft.ws wrapper. Each page is represented by an htmld wrapper. Wrappers nest according to the logical navigational structure of the site. On the end node you can appreciate the contents of a simple page. The stayInTouch.htmld wrapper holds a main HTML file (index.html) and a sibling file for feature information (featureList.html). Images and other supporting resources are found next to the files that reference them.
This approach works in several levels. It allows you to name graphics and resources generically, such as header.jpeg. However, the generic name works fine because more than likely there is only one header file, not a hundred. If you were using one general graphics directory, each graphic would need a unique name or some other cryptic-naming scheme. By localizing resources near their point of use, each name is descriptive, clear, and readable. This also removes a lot of the creativity involved in inventing filenames. The context of the file provides information about what it is, so you don't need to peek into the file to figure out what it contains.
This approach also allows you to create HTML template files. If you were going to add a product, it becomes a matter of duplicating one of the existing wrappers, updating new header.jpeg graphics and the new text. The rest remains the same. This makes you more efficient when you have to add or build a Web site because you can always leverage on previously done work.
From a maintenance point of view, the htmld approach helps to keep directories smaller and clutter free. From a security standpoint, it also lets you clearly see suspicious files that you didn't put there. If you know where and what your files are, you'll have a better chance of noticing if you've had a break-in or if someone put something in the wrong spot. If you just throw it all in together and have 30 or 40 files per directory, it becomes difficult to figure out what is going on, and it takes more careful reading. Later the site will have many stale HTML files or graphics that are no being longer used. Cleaning up at this point is time-consuming because you have to think about what each of the files contain. If you remove any haphazardly, more than likely you'll break something.
When you are creative with your filenames, it becomes more difficult to know what a file contains. What is header2.gif? I don't know because there's no context, and I doubt that the person who created such a file could remember either. If it's all packaged, then you know who's the client of that resource, and you can create a visual and organizational association; you know what things are.
I title everything firstSecondThird.type. The first word is in lowercase letters. Any word after has its first letter in uppercase. I don't use spaces, dashes, or any other character that is not a letter or a number. Periods are used to separate file extensions. This makes it easy for me to read and type filenames, and it removes the possibility of any nonalphanumeric characters from becoming part of a filename.
While you are building your site, you may want to clearly document the standards used for creating a site. For example, it is useful to document colors used on an image. Better yet, create template files that can be used for creating new graphics. In Adobe Photoshop, this is really easy. Add a layer and enter the size of the text and font face that you used for a graphic title. This will allow future titles to be consistent and will save you a lot of time in generating artwork. Pass this information to those that create artwork for your site. You'll be glad if you do.
Many of your users will be interested in creating their own personal home pages. Apache provides support for this feature with their UserDir module. If you performed the installation instructions in Chapter two, "Installing and Configuring an Apache Server," you'll recall that you disabled the UserDir functionality from your server. Requests for your users' home pages take the form of: http://host/~user, where user is the login name of the user.
On receiving a request for a user's home page, the default server configuration looks for the public_html directory inside of the user's home directory. I don't like this feature for security and convenience reasons.
If a user protects his directory, making it unreadable by the User ID (UID) of the server, then he doesn't have an opportunity to publish a home page. Other security implications are possible too, depending on the permissiveness of your configuration files and features such as automatic indexes. You can create a situation where a user could provide Web access to not only his files but to other directories in your system. This is something you really don't want to do!
Apache versions under 1.1 don't provide any configuration alternative, except for installing a third-party module that implements different functionality. If you are using version 1.1 or higher, you'll be glad to know that the version of the module allows you to specify a directory that contains all user's public HTML directories. Users are able to create and maintain their own Web pages while administrators are happy that their HTML directories are not located along with other potentially sensitive files.
An additional benefit of the improved module is that it allows you to create home page directories that don't necessarily match your internal usernames. Because this mechanism doesn't rely on a user account, it allows you to provide home pages even on a host that doesn't hold any user accounts, such as a bastion host for a site that has a firewall. Bastion hosts are machines that provide Internet services to the Internet.
You will need to provide some sort of mechanism to help users upload their information and publish it to the Web. In terms of security issues, you'll still have to deal with what they publish, but I'll leave that to your internal Web police. Let's assume that your organization doesn't have any disgruntled employees that would publish your most private secrets right off your Web site.
CGIs are programs that interact with your server via the Common Gateway Interface—a convention used for exchanging data between the server and a program. CGIs are necessary on your Web if you want to implement things such as forms or any type of advanced functionality. On the default configuration you installed in Chapter 2, CGIs were disabled.
The problem with CGIs and other executable processes is that they are programs. Security problems are usually introduced by bugs in programs. While your Web server is fairly secure, programs that you implement may not take into account some of the treachery that some people will go through to break into your site. With that said, realize that someone may be able to exploit a weakness on a CGI program you create. (For detailed information on this subject, see Chapter 16, "Other Security Issues.")
My first suggestion is that until you understand the ramifications of permitting public CGIs, you should restrain from offering this capability to your users. There are a few questions that you'll need to address before you can really provide an evaluation:
Once you understand what you are installing and what you are protecting against, it becomes easier to define a policy regarding the use and location of CGI programs on your site. The easiest approach is to read the source code of each CGI before you install it. However, this obviously doesn't scale well on large installations, especially where a lot of users may be creating programs. It becomes unfeasible to look in close detail at what each CGI does and the security implications of the program.
To enable CGI, you will need to uncomment the ScriptAlias directive in your conf/srm.conf file and restart the server. The ScriptAlias directive specifies a directory where the server can execute programs. By default, this is set to /usr/local/etc/httpd/cgi-bin/. This provides a restrictive setup because the server will only execute programs that are found in this directory.
Because the server restricts the execution of CGI to designated directories, the organizational structure previously presented would require that all CGIs live in a central location. While this may be fine for a small site, you may have to consider other alternatives and their security implications:
These options progressively lax on their security. I feel that the second option is a good compromise for the following reasons:
It allows enough freedom for the site designer while at the same time keeps things orderly.
This mechanism fits into my belief system that a site should be portable—the .htmld approach. If the entire site tree moves, all the resources are properly referenced locally within the tree itself.
The first option I find too restrictive for any site that supports virtual hosts (multiple domains) such as accessLINK.
The third option is actually the one that I implement at accessLINK. I choose it because we have a tight control on our CGI and what they do. If we had users on our system, this laissez-faire approach would not even be considered.
To enable CGI in predetermined directories, all you need to do is set an option that enables the execution of CGIs on a properly named directory. Use local-cgi for the name of local cgi directories. You can accomplish this with a <Directory> section in your global access control file, conf/access.conf, like in following example:
<Directory *.ws/local-cgi> AllowOverride None Options ExecCGI </Directory>
This configuration will allow execution of CGIs only if they are stored in a subdirectory of a Web site wrapper called local-cgi.
If your users have more than little technical inclination, it won't be long until you receive requests for setting up user-controlled CGI directories. This is often a source of headaches for you from a standpoint of establishing a security policy. Freedom equals problems. So the question is what do you do? If you need to give many people access and control over the CGIs they run, you've opened Pandora's box. My personal view is that as long as you are giving freedom, might as well give total freedom. Just make sure that freedom doesn't cause you other problems.
Another way of dealing with the problem, may be to provide several CGIs that can be accessed publicly within your organization. CGIs provide functionality such as e-mail, generic form support, page counters, search tools, and so on. This way you'll eliminate a great portion of the need for public CGIs.
If a user needs to implement a form, have her use your generic form wrapper. This CGI should e-mail the form information. The user could then write a program that will process the e-mail information into something useful to her.
Another alternative is to place a machine outside of your firewall that doesn't have anything but user home pages. Then you could set restrictions like the following in your global access configuration file (conf/access.conf):
<Directory /usr/local/etc/httpd/public/*/user-cgi> AllowOverride None Options ExecCGI </Directory>
Assuming that/public is your UserPath directory (using the UserPath module), users will be able to do what they want in their CGI directories. You can network mount the public directory so that it is easy for users to update and change what they want. However, in terms of access from the outside, no sensitive information would be available.
Organizing your site will help you become more efficient at managing your Web site(s). As things get handed down from one person to another, a strong and workable framework will help maintain some sort of order, which will allow for efficient maintenance and growth.
As the number of users increases, you'll face security issues that are tough to predict in terms of the potential problems they may create. The purpose of the Internet is to disseminate information. Having a overly restrictive or loose policy creates problems. A happy medium is perhaps found on an isolated machine that has been sanitized for the function. Users can then create and maintain their own pages without much concern for security implications that may affect sensitive areas of your network.
![]()
![]()
![]()
![]()
{kind=link}